Introduction
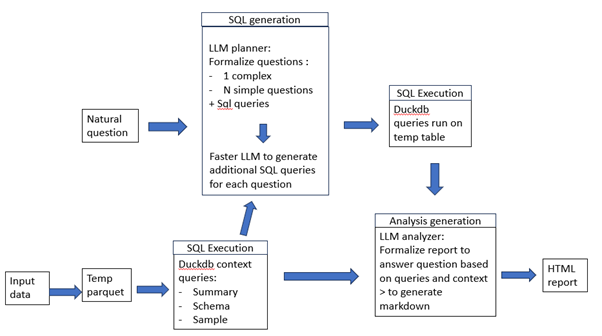
Goal: Show, step-by-step, how to leverage FME’s flexibility and orchestration, DuckDB, and LLMs to answer questions on a dataset.
Approach: We combine FME for robust ingestion, DuckDB for fast SQL+metadata, and three LLMs roles (Planner, SQL Generator, and Analyst) to produce queries and render an HTML report.
What you’ll get: A reusable FME workspace that converts any tabular input to Parquet, extracts schema/summary/sample, plans questions, runs SQL, and renders a markdown-to-HTML analysis.
Dataset:
An Excel file (Finnish headers) with daily cyclist counts per sensor location in Helsinki.
Example question:
Where are the places with more cyclists? When is it happening?
Template:
https://hub.safe.com/publishers/antoine/templates/llm_sql_report_demo
The main steps are:
- Convert any file to a temp Parquet with FME
- Execute simple analysis on the Parquet file with DuckDB to get metadata
- Ask the LLM, fed with metadata, to produce formalized questions and SQL queries able to answer the question
- Ask another, lighter, LLM to generate SQL queries based on the simpler/more formal questions of the first one.
- Run all the SQL queries with DuckDB on the complete temporary table
- LLM analyses the SQL answers in regards with the original task.
- FME and LLM together produce an HTML report, answering the global questions
1. Convert any file to Parquet
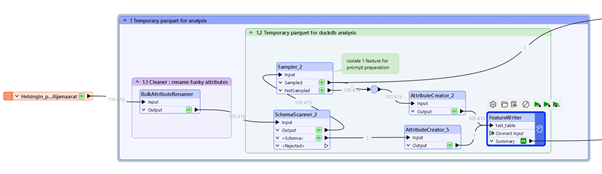
FME is a very powerful tool able to digest hundreds of formats into its own internal format. Our input here is a (peculiar…) Excel file in Finnish. We will dynamically convert it to Parquet:
- BulkAttributeRenamer allows us to replace all strange characters which could have slipped into our attribute names into “_”: [^\p{L}\p{N}_]
- SchemaScanner allows us to consolidate this updated schema
- FeatureWriter writes the data to Parquet, fed with both data and schema

2. Execute simple analysis
As we cannot feed the whole table to the LLM, we will feed it with metadata
- Table schema
- Statistical summary
- Sample
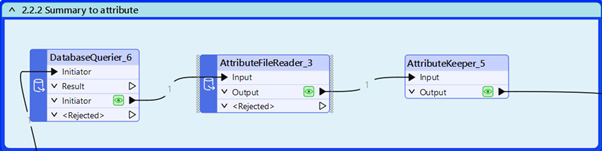
2.1 Produce schema
 DatabaseQuerier :
DatabaseQuerier :
| FME_SQL_DELIMITER | CREATE TABLE test_table AS SELECT * FROMread_parquet(‘@Value(_dataset)/test_table.parquet’) LIMIT 10;| EXPORT DATABASE ‘$(tempFolder)’;| DROP TABLE test_table;| |
We want the schema of the table to be sent in an “SQL” format, to the LLM. DuckDB, called in FME, allows us to do it with this set of queries:
This will generate a series of small files regarding our table, one, called “schema.sql” containing the CREATE TABLE.
- AttributeFileReader allows to read a file into an attribute, here the “schema.sql” fil
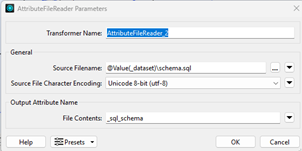
2.2 Produce Summary
DuckDB offers a Summarize statement (https://DuckDB.org/docs/stable/sql/statements/summarize). This gives a good idea about how each field is populated and is very important to know how to query the table. Here again, we read the result back to an attribute.
2.3 Produce a Sample
![]()
- Select * LIMIT 3 on the table
- ListBuilder to get only one feature
- AttributeJSONPacker to have it as one attribute
3. Call the LLM to generate questions and SQL
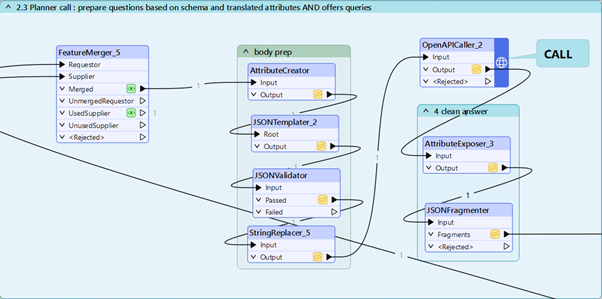
Here is a bit more of Json and trial/error part. We need to build a set of instructions, combining our new information with and our question so that the model answer in the expected way.
Depending on your use case and model, you might need to a different structure.
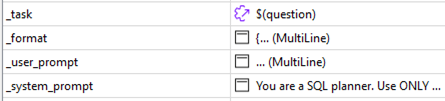
- Task is the main question, straight from the user
- Format is the definition of the structured output we want. As we want the process to work on any question, the answer must always follow a defined structure, so that we can continue the process.

- User prompt combines task, example of answer etc…

- System prompt sets the rules

With these prompts we get a Json output from where we can export formalized questions and their SQL. The speed and quality depend a lot on your model choice
In our case:
- the task is vague: where are the places with more cyclists? When is it happening?
- The table is a “not so well designed” Excel in Finnish
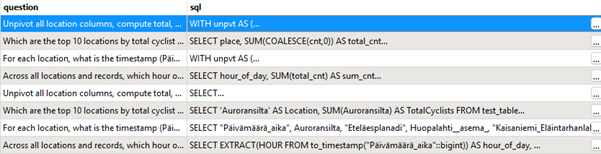
- The answer is:
![]()
The first query is trying to give a complex question/query to answer directly the question. The secondary questions/SQL queries are simpler ones, less likely to fail. All of them will later be sent to another LLM, faster and cheaper, to get again new queries. Depending on your mode, task and dataset, you might need more chances to get valid and useful ones.
4. Produce a new set of SQL queries based on the questions
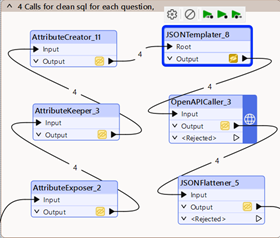
As our first LLM answer might contain mistakes, we will ask another one to implement all the previous questions through SQL. This gives room for error and a bit more variety at a low cost, as we are picking a cheaper/faster model for this. There is no need for it to understand the big task as it is answering the questions reframed by the first model.
The steps are the same:
- Prompt preparation


- API call
- JSONFlattener to come back to classical FME attribute
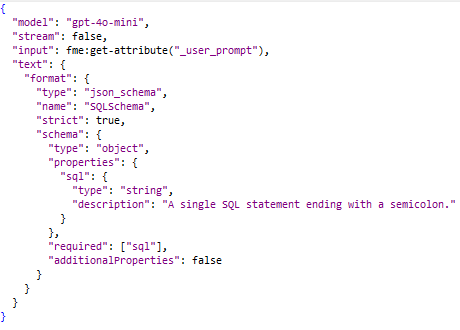
![]() As you can read, the prompt and the output format are simpler. We only require an “sql” element.
As you can read, the prompt and the output format are simpler. We only require an “sql” element.
We now have a set of 8 queries: 4 from the planner and 4 from the secondary call.
5. Run the SQL queries
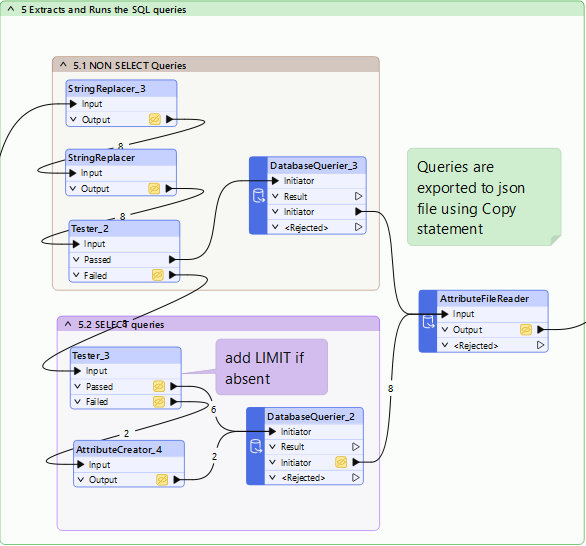
As an SQL query, in FME return n objects with an unknown schema, we chose to use the COPY statement. We could also have used the ListBuilder + AttributeJSONPacker but the resulting Json might be a bit further than the original answer.
This implies that we remove the ending “;” from the queries with StringReplacer.
As “Copy” supports only Select statement, we put the other queries into a SELECT one
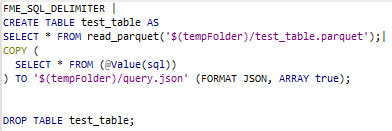
For SELECT statements, it is simpler, we just added “LIMIT 30” at the end of the queries to avoid big output files:
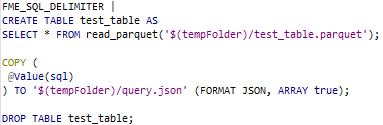
Once again, the output file is then read to an attribute.
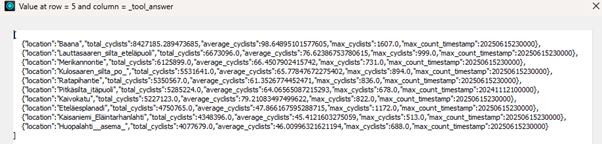
6. LLM analysis and markdown report generation
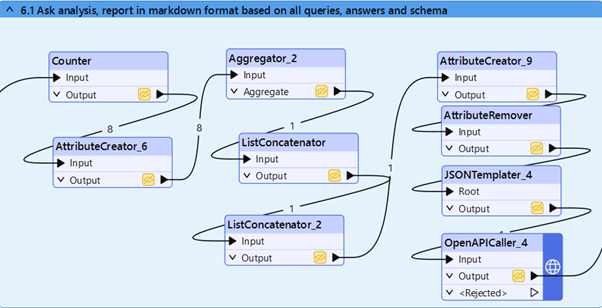
Once we have collected all this information, FME shines in restructuring it to prepare for the LLM analysis. A combo of text and Json transformer can make any kind of prompt.
- System prompt:

As you can see, nothing is specific, just rules. We chose Markdown as it is very light in terms of token but good as expressing a structure. Nothing prevents to summarize, translate, or make the report prettier later with cheaper models.
- User prompt:
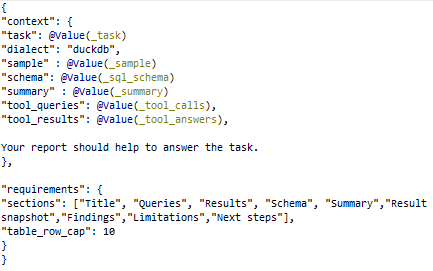
This prompt tries to aggregate all relevant information we collected and gives a “structure” to the analysis.
Body:
The format is specified, as always to allow an easy integration with the rest of the process. We chose a smarter model as there is a lot of info to articulate while keeping in mind the original task. Actually, gpt5 is even better but much more expensive.
7. Report to HTML
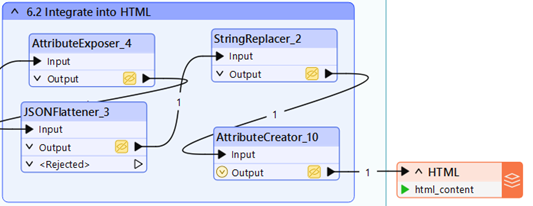
Once we got our Markdown report, it is very easy to translate it into whatever output you want. We chose to put it into an HTML file.
For this we have an HTML attribute with a placeholder for the markdown element, we just put our report there.
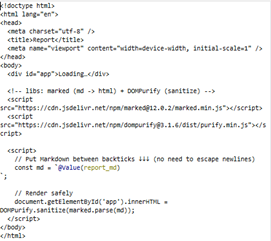
Once this text is ready, an HTML writer places it wherever needed.

Congratulations! The report is pretty neat, the parts about limitations and next steps are important as they can hint you about 2 things:
- Did the model go wild and invent things
- Could I ask for a second round, with better questions, based on this output (agentic behavior).
Conclusion
By separating ingestion, profiling, planning, querying, analysis, and reporting, we turned a messy Excel file with Finnish headers into clear answers about Helsinki’s cycling patterns, without hand-crafting every SQL statement. FME handled the orchestration and format wrangling, DuckDB provided fast, local SQL over Parquet, and three focused LLM roles (Planner → SQL Generator → Analyst) kept the workflow reliable and cost-aware.
The result is a reusable pipeline you can point at almost any dataset to go from question → queries → insightful HTML report.
Just as important as the outcome is the discipline behind it: only small, meaningful slices of data (schema, summary stats, sample rows) went to the models; we enforced guardrails around SQL execution (COPY (SELECT …), semicolon stripping, result caps); and we made the analyst step reason over named result sets instead of raw tables. This keeps the LLMs in their lane and the data work where it belongs.
What you now have
- A template workspace that standardizes any table to Parquet and profiles it for downstream intelligence.
- A repeatable prompting pattern: Planner for structure, lighter model for SQL, heavier model for synthesis.
- A reporting path that turns Markdown into shareable HTML with minimal glue.
Where to take it next
- Define each main step as an independent process to build flexible Automations in FME Flow.
- Complete the report with trustable “raw” metadata and summaries from profiling tools like Pandas profiling.
Final thought
The power here isn’t just that LLMs can write SQL, it’s that, with the right boundaries and roles, they help you ask better questions and automate the boring parts. Keep the contracts between steps tight, measure what matters (quality, cost, latency), and this pattern will scale from a single Helsinki bike counter to your entire data estate.

 Suomi
Suomi English
English
