A year ago we published a step-by-step tutorial on translating Word documents with FME and AI. Back then we used Helsinki-NLP/opus-mt-fi-en (MarianMT) and handled DOCX as XML. It was fast and accurate, but the Python venv + XML workflow felt heavy.
Since then, FME’s Word integration improved and a smaller Finnish model, Poro, became easy to run locally via Ollama. That makes a lighter tutorial possible ( Thanks Oliver Morris for the suggestion).
Introduction
Goal
- Translate DOCX EN→FI in FME using a local 8B Finnish LLM (Poro) via Ollama.
Requirements
- FME 2024.2 or later
- Ollama
Template
https://hub.safe.com/publishers/antoine/templates/docx_translation_ollama_demo
Pros/cons?
➕Generic: works with any FME format that produces text elements
➕ No XML juggling: preserves layout well enough for simple/typical docs
➕Local by default: great for internal/private documents
➖ Throughput: MarianMT still wins for raw speed at scale
➖ Complex layouts: XML may be better for highly structured or unusual DOCX
Main steps
This time we will:
- Parse the DOCX with FME Word Reader
- Filter the text elements
- Translate them with Poro (Through Ollama)
- Update the text element’s text attribute
- Write using the FME Word Writer
As you can see, less hassle than last year.
1) Parse the document with the FME Word Reader
For those who don’t use FME, this might seem complicated, but you just need to drag and drop your Word document into the workbench interface. FME will take care of recognizing the format and setting default parameters. A box appears and you can start the process to see how FME digests the content.
Note: the Word Reader uses a Python library behind the scenes and doesn’t support every DOCX element, so some items may be lost.
2) Filter & normalize the text elements
We want to translate text elements without losing position or style. This implies three things:
- Give them an ID to keep the feature order : Counter
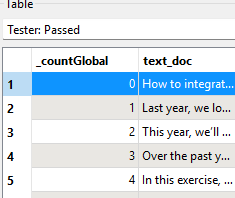
- Filter out the text elements from rasters and others: Tester
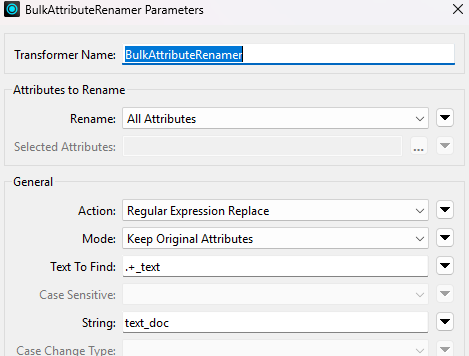
- Put the original text into one attribute so the LLM can translate those values: BulkAttributeRenamer
3) Translate them with Poro (Through Ollama)
Here comes the heart of the process. We need to access the model, feed the model with our text and then hope for the best!
- To access the model is simpler than we expected as an Ollama-compatible version is published on Hugging Face! Even if you cannot see it on Ollama website, you can download the model by typing this in your command line (with Ollama installed and running).
ollama pull hf.co/mradermacher/Llama-Poro-2-8B-Instruct-GGUF:latest
- To feed the text, multiple approaches are possible, depending on your available resources. Here are the steps we took:
- Create blocks of text to give the model a context, not too long (slower, memory issues) and not too short (to avoid out of context translations)
- Make a first query to feed the model with this block as context
- Make one new query per fme feature (contained in the block), asking the model to translate it taking into account the context.
This allows to get good translation while keeping a 1-1 relationship between translated elements and original ones.
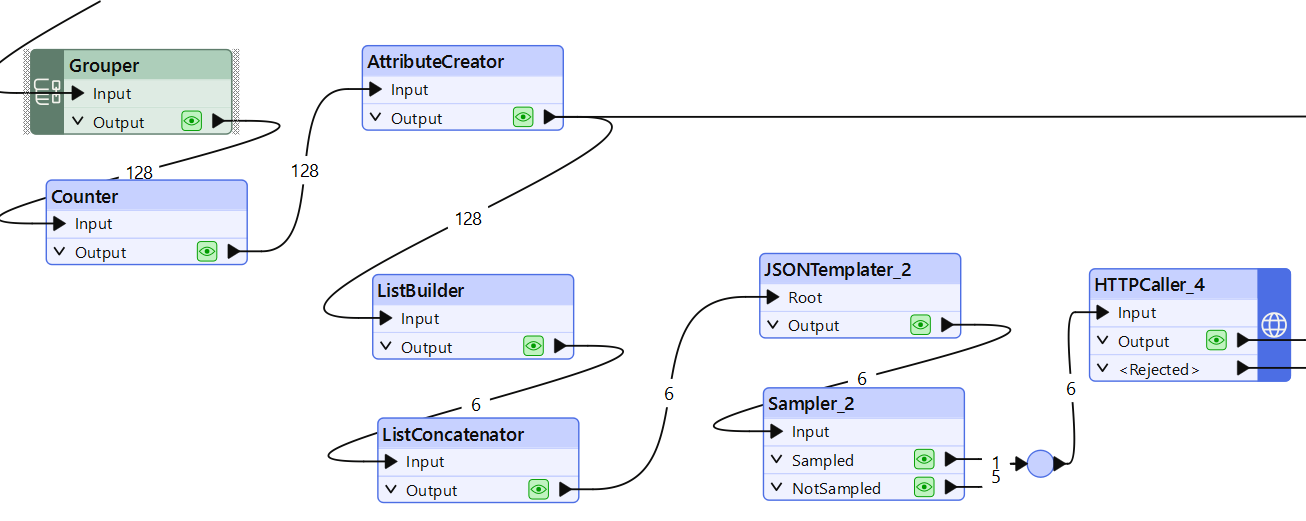
For the first two steps, we Grouped the features by a given amount (here 25) and concatenated their text into a paragraph (ListConcatenator). Then a JSONTemplater allows to form a clean json to send as body to our model.
{ "model" : "hf.co/mradermacher/Llama-Poro-2-8B-Instruct-GGUF:latest", "system" : "You are a professional EN→FI translator.", "prompt" : "REFERENCE CONTEXT ONLY — DO NOT TRANSLATE ANYTHING.\\nReply with exactly: OK\\n\\n<<>>\\nChange the model.\nTry to force the output structure.\nClip the image into different parts using Tiler and send them to see if it gives better results\\n<<>>", "options" : { "temperature" : 0, "num_predict" : 3 }, "stream" : false, "keep_alive" : 15 }
For the last step, we add the context we got back from the previous call. Each element receives the context of its block.
{
"model": "$(model)",
"system": "You are a professional EN→FI translator.",
"prompt": concat("You already have the REFERENCE CONTEXT. Do not translate that.\nNow translate ONLY this element into Finnish:\n",fme:get-attribute("_element"),""),
"context": ["AAAAA"],
"options": { "temperature": 0.0, "num_predict": 400 },
"stream": false,
"keep_alive": "30m"
}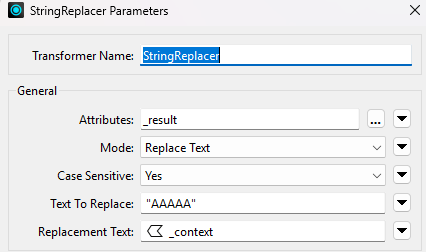
You see in the JsonTemplater extract that I put “AAAAA” as placeholder. it is replaced by the proper context values with StringReplacer. FME flexibility is very nice for this kind of dynamic queries. As an important note, JSONTemplater supports XQueries (as you can see the function “concat” here, it is a very powerful tool).
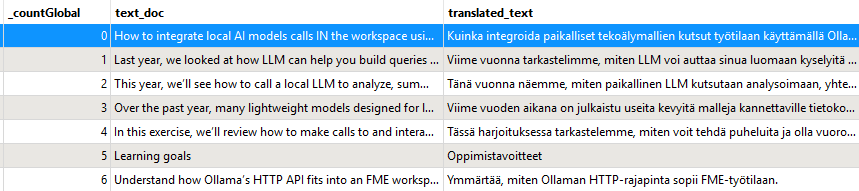
All our elements are translated! We kept a global id. This will allow us to merge/join with original entities before writing.
Update the text element’s text attribute
We now have the translated elements but they are in a new attribute (“translated_text”). We need push the values to the existing attributes defined in FME Docx format. FME has not mapped all text values to a single attribute but created one by type of Word element. To bypass this we will push the new text value to all of them. FME will take the one it needs at the end.
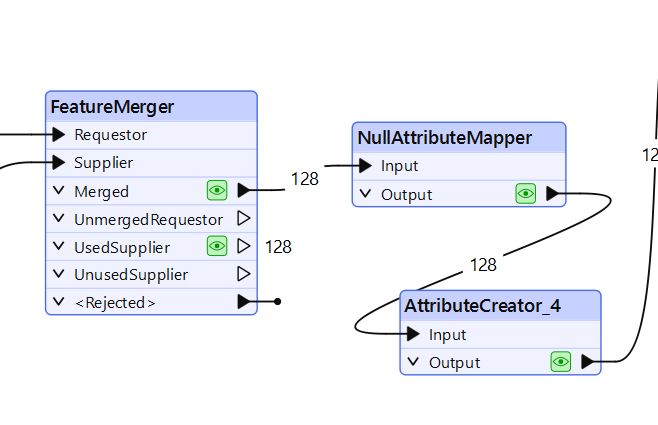
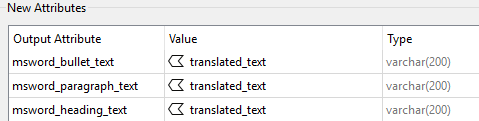
Write using the FME Word Writer
We now have the Finnish version of the text pushed to the features, the writing is as simple as possible. Push the result into a Word Writer, push start, go grab a coffee cup and wait for your translated document.
Conclusion
You’ve built a generic, local Word-translation workflow with FME + Poro (via Ollama). It’s easy to adapt to other FME-readable formats with text features. The project is available on FMEHub! Don’t hesitate to contact us if you want us to help you leverage your data!

 Suomi
Suomi Svenska
Svenska
