Vuosi sitten julkaisimme vaiheittaisen oppaan Word-asiakirjojen kääntämisestä FME:n ja tekoälyn avulla. Silloin käytimme mallia Helsinki-NLP/opus-mt-fi-en (MarianMT) ja käsittelimme DOCX-tiedostoja XML:nä. Ratkaisu oli nopea ja tarkka, mutta Python-venv + XML -työnkulku tuntui raskaalle.
Sen jälkeen FME:n Word-integraatio on kehittynyt ja pienempi suomenkielinen malli, Poro, on tullut helpoksi ajaa paikallisesti Ollaman kautta. Siksi kevyempi ohje on nyt mahdollinen (kiitos Oliver Morris ideasta).
Johdanto
Tavoite
- Kääntää DOCX-asiakirja englannista suomeksi (EN→FI) FME:ssä käyttäen paikallista 8B suomenkielistä LLM-mallia (Poro) Ollaman kautta.
Vaatimukset
- FME 2024.2 tai uudempi
- Ollama
Mallipohja
https://hub.safe.com/publishers/antoine/templates/docx_translation_ollama_demo
Päävaiheet
ällä kertaa teemme seuraavaa:
-
Parsimme DOCX-tiedoston FME Word Readerilla
-
Suodatamme teksti-elementit
-
Käännämme ne Porolla (Ollaman kautta)
-
Päivitämme teksti-elementin tekstiattribuutin
-
Kirjoitamme tuloksen FME Word Writerilla
1) Jäsennä asiakirja FME Word Readerilla
Niille, jotka eivät käytä FME:tä, tämä saattaa näyttää monimutkaiselta, mutta käytännössä riittää, että vedät ja pudotat Word-asiakirjan Workbenchin näkymään. FME tunnistaa formaatin ja asettaa oletusparametrit automaattisesti. Näytölle ilmestyy lukulaatikko ja voit käynnistää prosessin nähdäksesi, miten FME pilkkoo sisällön.
Huom: Word Reader käyttää taustalla Python-kirjastoa eikä tue kaikkia DOCX-elementtejä, joten osa kohteista saattaa hävitä.
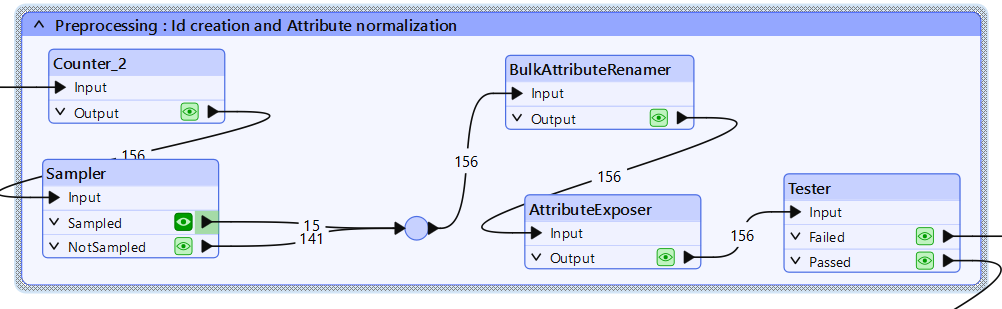
2) Suodata ja normalisoi teksti-elementit
Haluamme kääntää teksti-elementit menettämättä niiden sijaintia tai tyyliä. Tämä tarkoittaa kolmea asiaa:
-
Annetaan niille ID, jotta piirteiden järjestys säilyy: Counter
-
Suodatetaan teksti-elementit erilleen rastereista ja muista: Tester
-
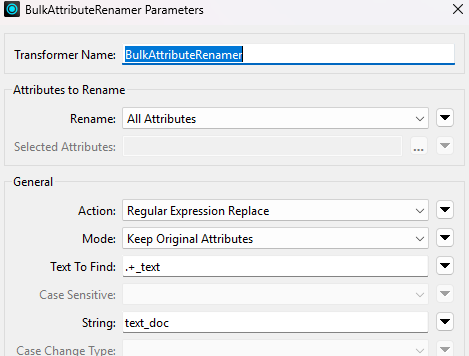
Laitetaan alkuperäinen teksti yhteen attribuuttiin, jotta LLM voi kääntää nämä arvot: BulkAttributeRenamer
3) Käännä tekstit Porolla (Ollaman kautta)
Tässä on prosessin ydin. Meidän täytyy päästä käsiksi malliin, syöttää sille teksti ja toivoa parasta!
- Malliin käsiksi pääseminen on helpompaa kuin odotimme, sillä Ollama-yhteensopiva versio on julkaistu Hugging Facessa! Vaikka mallia ei näykään Ollaman sivuilla, voit ladata sen komennolla (kun Ollama on asennettu ja käynnissä).
ollama pull hf.co/mradermacher/Llama-Poro-2-8B-Instruct-GGUF:latest
-
Tekstin syöttämiseen on useita vaihtoehtoja, riippuen käytettävissä olevista resursseista. Me teimme näin:
-
Loimme tekstilohkoja, jotka antavat mallille kontekstin – eivät liian pitkiä (muuten hidasta ja muistisyöppöä) eivätkä liian lyhyitä (jottei käännös irtoa kontekstista).
-
Teimme ensimmäisen kyselyn, jossa syötimme mallille tämän lohkon pelkkänä kontekstina.
-
Teimme sen jälkeen yhden uuden kyselyn jokaista FME-featurea kohden (lohkossa), pyytäen mallia kääntämään juuri sen ottaen huomioon kontekstin.
Näin saadaan hyvä käännös ja säilytetään 1–1-suhde alkuperäisten ja käännettyjen elementtien välillä.
-
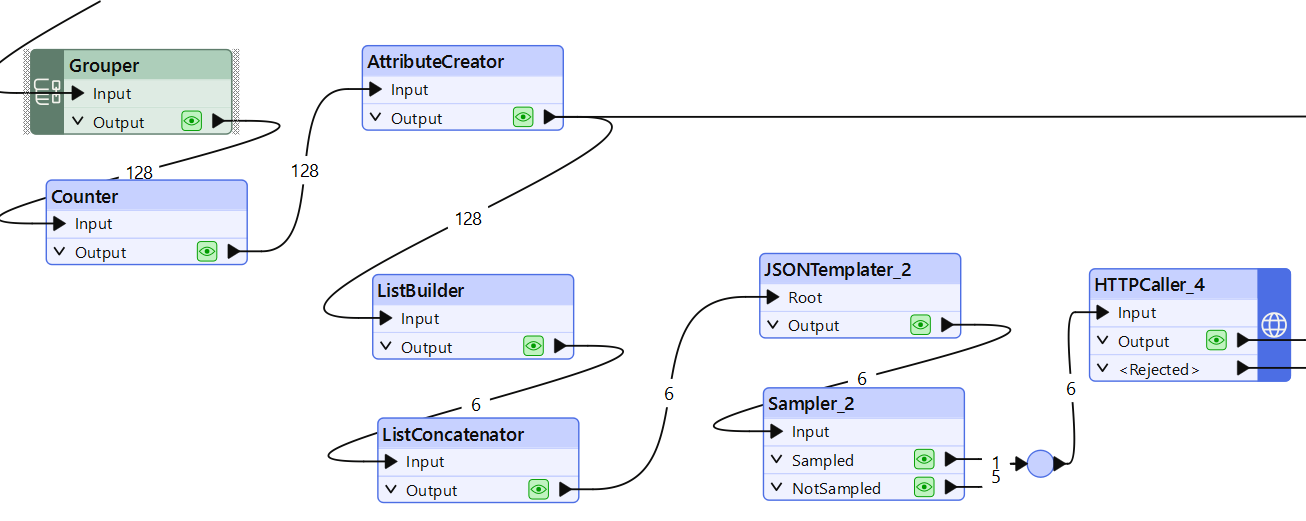
Ensimmäisiä kahta vaihetta varten ryhmittelimme featuret tietyn määrän mukaan (tässä 25 kpl) ja yhdistimme niiden tekstit yhdeksi kappaleeksi (ListConcatenator). Sen jälkeen JSONTemplater muodosti siistin JSON-rungon, jonka lähetämme mallille pyynnön rungoksi.
{ "model" : "hf.co/mradermacher/Llama-Poro-2-8B-Instruct-GGUF:latest", "system" : "You are a professional EN→FI translator.", "prompt" : "REFERENCE CONTEXT ONLY — DO NOT TRANSLATE ANYTHING.\\nReply with exactly: OK\\n\\n<<>>\\nChange the model.\nTry to force the output structure.\nClip the image into different parts using Tiler and send them to see if it gives better results\\n<<>>", "options" : { "temperature" : 0, "num_predict" : 3 }, "stream" : false, "keep_alive" : 15 }
Viimeisessä vaiheessa lisäämme kontekstin, jonka saimme takaisin edellisestä kutsusta. Jokainen elementti saa oman lohkonsa kontekstin.
{
"model": "$(model)",
"system": "You are a professional EN→FI translator.",
"prompt": concat("You already have the REFERENCE CONTEXT. Do not translate that.\nNow translate ONLY this element into Finnish:\n",fme:get-attribute("_element"),""),
"context": ["AAAAA"],
"options": { "temperature": 0.0, "num_predict": 400 },
"stream": false,
"keep_alive": "30m"
}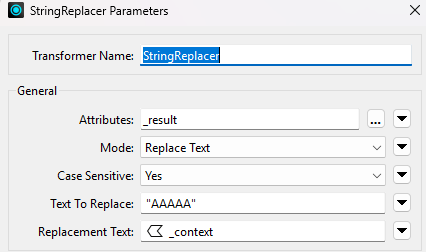
Kuten JSONTemplater-esimerkistä näkyy, laitoin “AAAAA” paikalleen vain paikkamerkiksi. StringReplacer korvaa sen myöhemmin oikeilla kontekstiarvoilla. FME:n joustavuus on todella hyödyllistä tällaisissa dynaamisissa kyselyissä. Tärkeä huomio on myös se, että JSONTemplater tukee XQuery-lausekkeita (kuten tässä näkyvä concat-funktio) – se on erittäin tehokas työkalu.
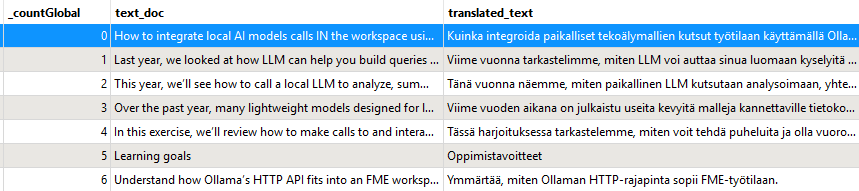
Kaikki elementit on nyt käännetty! Säilytimme niille globaalin ID:n, jonka avulla voimme yhdistää ne alkuperäisiin entiteetteihin ennen kirjoittamista.
Päivitä teksti-elementin tekstiattribuutti
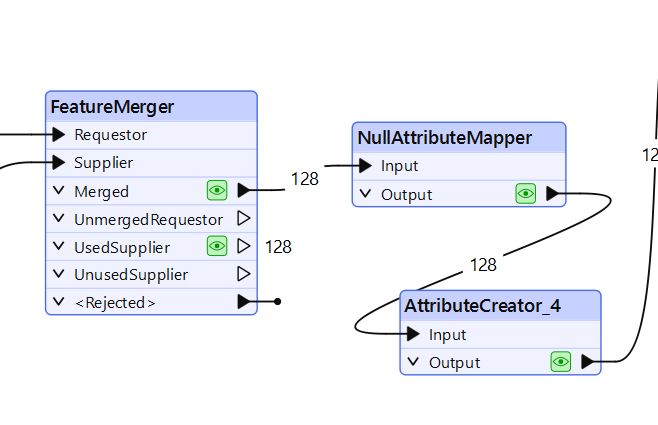
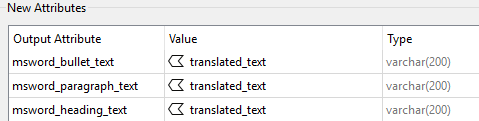
Meillä on nyt käännetyt elementit, mutta ne ovat uudessa attribuutissa (“translated_text”). Meidän pitää siirtää nämä arvot olemassa oleviin attribuutteihin, jotka FME:n DOCX-formaatti määrittelee. FME ei kartoita kaikkea tekstiä yhteen ainoaan attribuuttiin, vaan luo eri attribuutin kullekin Word-elementtityypille. Tämän kiertämiseksi kopioimme uuden tekstiarvon kaikkiin näihin tekstiattribuutteihin – FME poimii lopuksi sen, jota se tarvitsee.
Kirjoita asiakirja FME Word Writerilla
Meillä on nyt suomenkielinen versio tekstistä piirteiden attribuuteissa, joten kirjoitusvaihe on mahdollisimman suoraviivainen. Syötä tulos Word Writeriin, paina Start ja anna FME:n luoda käännetty Word-asiakirja puolestasi.
Yhteenveto
Olet rakentanut geneerisen, paikallisesti ajettavan Word-käännöstyönkulun FME:n ja Poron (Ollaman kautta) avulla. Sitä on helppo mukauttaa myös muihin FME:n lukemiin formaatteihin, joissa on teksti-featureja. Projekti on saatavilla FMEHubissa! Ota rohkeasti yhteyttä, jos haluat apua datasi parempaan hyödyntämiseen!

 Svenska
Svenska English
English
