Johdanto
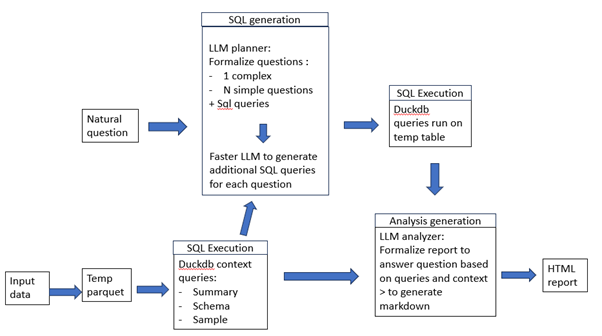
Tavoite: Näyttää vaiheittain, miten hyödynnetään FME:n joustavuutta ja orkestrointia, DuckDB:tä ja LLM:iä vastaamaan kysymyksiin aineistosta.
Lähestymistapa: Yhdistämme FME:n vankan ingestoinnin, DuckDB:n nopean SQL+metadata-käsittelyn ja kolme LLM-roolia (Planner, SQL Generator ja Analyst) tuottamaan kyselyt ja renderöimään HTML-raportin.
Mitä saat: Uudelleenkäytettävä FME-työtila, joka muuntaa minkä tahansa taulukkomuotoisen syötteen Parquet-muotoon, poimii skeeman/tiivistelmän/otoksen, suunnittelee kysymykset, ajaa SQL:t ja tuottaa markdownista HTML-analyysin.
Aineisto:
Mallipohja:
https://hub.safe.com/publishers/antoine/templates/llm_sql_report_demo
Esimerkkikysymys:
Missä on eniten pyöräilijöitä? Milloin se tapahtuu?
Päävaiheet ovat:
- Muunna mikä tahansa tiedosto väliaikaiseksi Parquetiksi FME:llä
- Suorita yksinkertainen analyysi Parquet-tiedostolle DuckDB:llä saadaksesi metatiedot
- Pyydä LLM:ää, jolle on syötetty metatiedot, tuottamaan formalisoituja kysymyksiä ja SQL-kyselyjä, joilla kysymykseen voidaan vastata
- Pyydä toista, kevyempää LLM:ää generoimaan SQL-kyselyt ensimmäisen mallin yksinkertaisempien/muodollisempien kysymysten pohjalta
- Aja kaikki SQL-kyselyt DuckDB:llä koko väliaikaisessa taulussa
- LLM analysoi SQL-vastaukset suhteessa alkuperäiseen tehtävään
- FME ja LLM tuottavat yhdessä HTML-raportin, joka vastaa kokonaiskysymyksiin
1. Muunna mikä tahansa tiedosto Parquetiksi
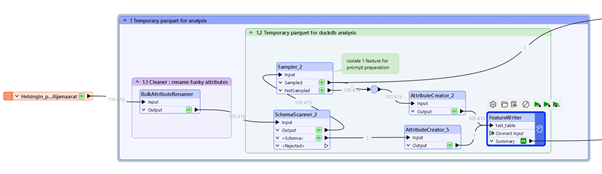
FME on erittäin tehokas työkalu, joka pystyy käsittelemään satoja formaatteja sisäiseen muotoonsa. Tässä syötteenä on (hieman erikoinen) suomenkielinen Excel. Muunnamme sen dynaamisesti Parquet-muotoon:
- BulkAttributeRenamer auttaa korvaamaan kaikki erikoismerkit, joita on voinut lipsahtaa attribuuttinimiin, alaviivalla ”_”: [^\p{L}\p{N}_]
- SchemaScanner konsolidoi päivitetyn skeeman
- FeatureWriter kirjoittaa datan Parquet-muotoon, jolle syötetään sekä data että skeema

2. Suorita yksinkertainen analyysi
Koska emme voi syöttää koko taulukkoa LLM:lle, syötämme sille metatiedot
- Taulun skeema
- Tilastollinen yhteenveto
- Otos
2.1 Tuota skeema
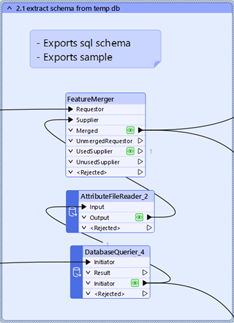
- DatabaseQuerier
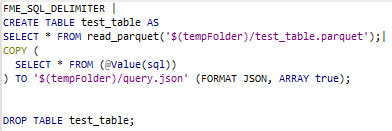
Haluamme lähettää taulun skeeman LLM:lle ”SQL”-muodossa. DuckDB, jota kutsutaan FME:stä, mahdollistaa tämän seuraavalla kyselysarjalla:
| FME_SQL_DELIMITER | CREATE TABLE test_table AS SELECT * FROMread_parquet(‘@Value(_dataset)/test_table.parquet’) LIMIT 10;| EXPORT DATABASE ‘$(tempFolder)’;| DROP TABLE test_table;| |
Tämä tuottaa joukon pieniä tiedostoja taulusta; yksi niistä, ”schema.sql”, sisältää CREATE TABLE -lauseen.
- AttributeFileReader lukee tiedoston attribuuttiin — tässä ”schema.sql”-tiedoston.
2.2 Tuota yhteenveto
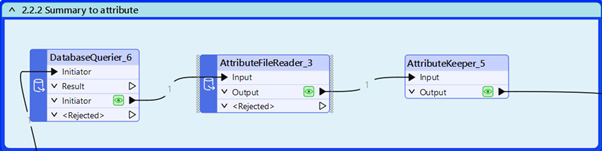
DuckDB tarjoaa Summarize-lauseen (https://DuckDB.org/docs/stable/sql/statements/summarize). Tämä antaa hyvän kuvan siitä, miten kukin kenttä on täytetty ja on tärkeä taulun kyselyjen suunnittelussa. Tässäkin luemme tuloksen takaisin attribuuttiin.
2.3 Tuota otos
![]()
- Select * LIMIT 3 taulusta
- ListBuilder, jotta saadaan vain yksi feature
- AttributeJSONPacker, jotta se on yhdessä attribuutissa
3. Kutsu LLM tuottamaan kysymykset ja SQL
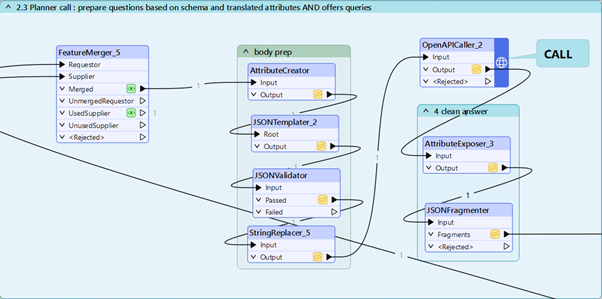
Tässä tulee hieman enemmän JSONia ja kokeilua. Meidän pitää rakentaa ohjeistus, joka yhdistää uudet tiedot ja kysymyksemme niin, että malli vastaa odotetulla tavalla.
Käyttötapauksesta ja mallista riippuen rakenne voi vaihdella.
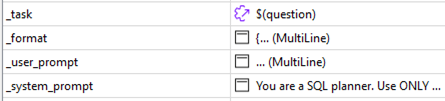
- Task on käyttäjän varsinainen kysymys.
- Format määrittelee halutun jäsennellyn ulostulon. Koska prosessin on toimittava mille tahansa kysymykselle, vastauksen on aina noudatettava määriteltyä rakennetta, jotta voimme jatkaa prosessia.

- User prompt yhdistää tehtävän, vastausesimerkin jne.

- System prompt asettaa säännöt

Näillä promptilla saamme JSON-ulostulon, josta voidaan viedä formalisoidut kysymykset ja niiden SQL. Nopeus ja laatu riippuvat vahvasti mallivalinnasta.
Meillä:
- Tehtävä on väljä: missä on eniten pyöräilijöitä? milloin se tapahtuu?
- Taulu on ”ei niin hyvin suunniteltu” Excel suomeksi.
- Vastaus on:
![]()
Ensimmäinen kysely yrittää antaa monimutkaisen kysymyksen/kyselyn vastatakseen suoraan kysymykseen. Toissijaiset kysymykset/SQL-kyselyt ovat yksinkertaisempia ja todennäköisemmin onnistuvat. Kaikki lähetetään myöhemmin toiselle, nopeammalle ja edullisemmalle LLM:lle tuottamaan uusia kyselyitä. Mallista, tehtävästä ja aineistosta riippuen saatat tarvita useampia yrityksiä saadaksesi kelvollisia ja hyödyllisiä tuloksia.
4. Tuota uusi joukko SQL-kyselyjä kysymysten pohjalta
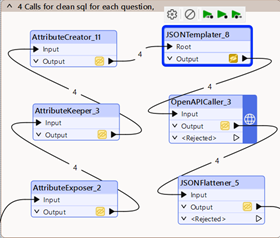
Koska ensimmäisen LLM:n vastaus voi sisältää virheitä, pyydämme toista mallia toteuttamaan kaikki aiemmat kysymykset SQL:nä. Tämä antaa pelivaraa virheille ja lisää vaihtelua edullisesti, koska valitsemme halvemman/nopeamman mallin. Sen ei tarvitse ymmärtää koko tehtävää, koska se vastaa ensimmäisen mallin uudelleenmuotoilemiin kysymyksiin.
Vaiheet ovat samat:
- Promptin valmistelu


- API-kutsu
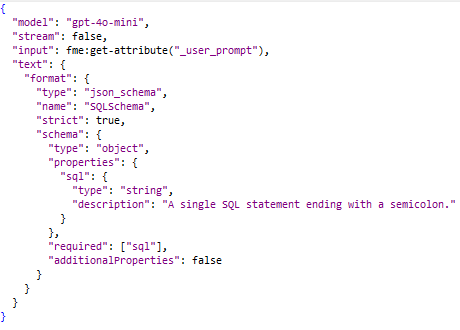
- JSONFlattener palatakseen klassisiin FME-attribuutteihin
![]()
Kuten näet, prompti ja ulostulon muoto ovat yksinkertaisemmat. Vaadimme vain ”sql”-elementin.
Nyt meillä on 8 kyselyä: 4 plannerilta ja 4 toissijaisesta kutsusta.
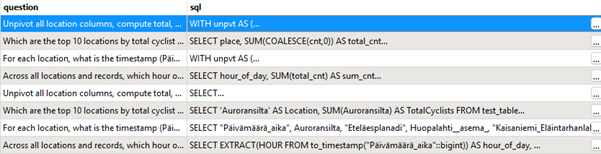
5. Aja SQL-kyselyt
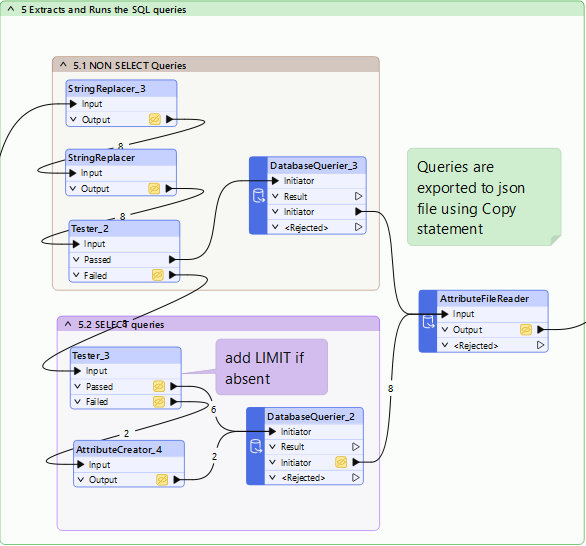
Koska SQL-kysely FME:ssä palauttaa n objektia tuntemattomalla skeemalla, päätimme käyttää COPY-lausetta. Voisimme myös käyttää ListBuilder + AttributeJSONPacker -yhdistelmää, mutta tuloksena oleva JSON olisi voinut olla kauempana alkuperäisestä vastauksesta.
Tämä tarkoittaa, että poistamme loppu-”;”-merkin StringReplacerilla.
Koska ”COPY” tukee vain SELECT-lauseita, laitamme muut kyselyt SELECTin sisään.
SELECT-lauseille se on yksinkertaisempaa: lisäsimme vain ”LIMIT 30” kyselyiden loppuun, jotta vältymme suurilta tulostiedostoilta.
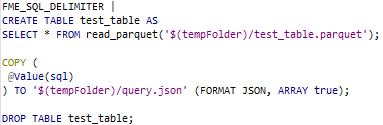
Luemme jälleen ulostulotiedoston attribuuttiin.
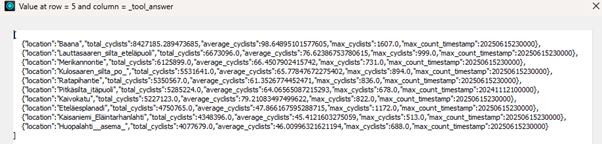
6. LLM-analyysi ja markdown-raportin generointi
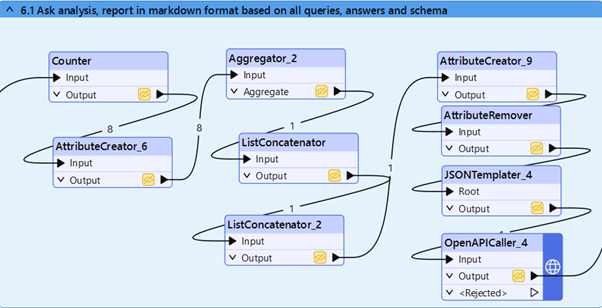
Kun olemme koonneet kaiken tarvittavan, FME loistaa sen uudelleenjäsentelyssä LLM-analyysiä varten. Teksti- ja JSON-transformereiden yhdistelmällä voi rakentaa minkä tahansa mallisen promptin.
- System prompt:

Kuten näet, mikään ei ole aineistokohtaista — ainoastaan säännöt. Valitsimme Markdownin, koska se on kevyt tokeneiden kannalta mutta riittävän ilmaisukykyinen rakenteeseen. Mikään ei estä tiivistämästä, kääntämästä tai kaunistamasta raporttia myöhemmin edullisemmilla malleilla.
- User prompt:
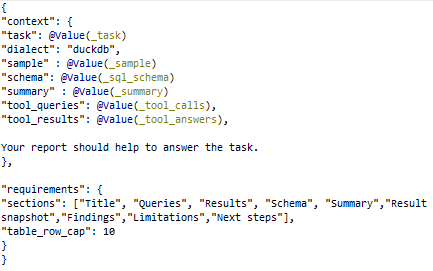
Tämä prompti kokoaa yhteen kaiken kerätyn olennaisen informaation ja antaa analyysille ”rungon”.
Body:
Muoto määritetään, kuten aina, helppoa integrointia varten. Valitsemme tässä älykkäämmän mallin, koska tietoa on paljon ja se pitää sovittaa alkuperäiseen tehtävään. Itse asiassa gpt5 on vielä parempi, mutta selvästi kalliimpi.
7. Raportti HTML:ksi
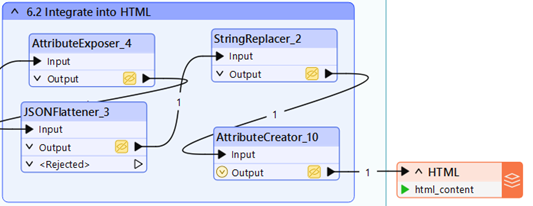
Kun Markdown-raportti on valmis, sen voi kääntää helposti mihin tahansa ulostulomuotoon. Me valitsimme HTML-tiedoston.
Tätä varten meillä on HTML-attribuutti, jossa on placeholder markdown-elementille — sijoitamme raportin siihen.
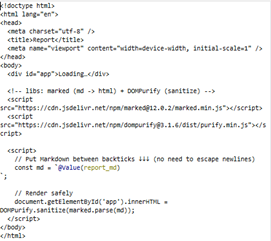
Kun teksti on valmis, HTML-writer sijoittaa sen haluttuun paikkaan.

Onneksi olkoon! Raportti on siisti — kohdat rajoitteista ja seuraavista askelista ovat tärkeitä, koska ne vihjaavat kahdesta asiasta:
- Menikö malli liikaa oman mielikuvituksen varaan?
- Voisiko pyytää toista kierrosta paremmilla kysymyksillä tämän ulostulon pohjalta (agenttimainen toiminta)?
Yhteenveto
Erottamalla ingestoinnin, profiloinnin, suunnittelun, kyselyn, analyysin ja raportoinnin pystyimme muuttamaan sekavan, suomenkielisen Excel-taulukon selkeiksi vastauksiksi Helsingin pyöräilykuvioista ilman käsin kirjoitettuja SQL-lauseita. FME hoiti orkestroinnin ja formaattien käsittelyn, DuckDB tarjosi nopean, paikallisen SQL:n Parquetin päälle, ja kolme fokusoitua LLM-roolia (Planner → SQL Generator → Analyst) pitivät työnkulun luotettavana ja kustannustietoisena.
Tuloksena on uudelleenkäytettävä putki, jonka voi suunnata lähes mihin tahansa aineistoon, ja edetä kysymyksestä → kyselyihin → oivaltavaan HTML-raporttiin.
Yhtä tärkeää kuin tulos on kurinalaisuus sen takana: vain pieniä, merkityksellisiä tietoviipaleita (skeema, yhteenvetotilastot, esimerkkirivit) lähetettiin malleille; laitoimme kaiteet SQL-suorituksen ympärille (COPY (SELECT …), puolipisteen poisto, tulosrajoitukset); ja ohjasimme analyytikkovaiheen päättelemään nimetyistä tulosjoukoista eikä raakadata-tauluista. Näin LLM:t pysyvät omalla tontillaan ja varsinainen datatyö siellä missä sen kuuluukin olla.
Mitä nyt on käsissä
- Template-työtila, joka standardoi minkä tahansa taulun Parquetiksi ja prof iloi sen jatkoälyä varten.
- Toistettava promptimalli: Planner rakenteelle, kevyempi malli SQL:lle, raskaampi malli synteesille.
- Raportointipolku, joka muuntaa Markdownin jaettavaksi HTML:ksi vähällä liimalla.
Minne seuraavaksi
- Määritä kukin päävaihe omaksi prosessikseen, jotta voit rakentaa joustavia automaatioita FME Flow’hun.
- Täydennä raporttia luotettavilla ”raakametatiedoilla” ja yhteenvedoilla profilointityökaluista, kuten Pandas profiling.
Lopuksi
Voima ei ole vain siinä, että LLM:t osaavat kirjoittaa SQL:ää — vaan siinä, että oikeilla rajoilla ja rooleilla ne auttavat kysymään parempia kysymyksiä ja automatisoimaan tylsät osuudet. Pidä vaiheiden väliset sopimukset tiukkoina, mittaa olennaista (laatu, kustannus, viive), niin tämä malli skaalautuu yksittäisestä Helsingin pyörälaskurista koko datakantaan.

 Svenska
Svenska English
English
