
RAG:n (Retrieval-Augmented Generation) tutkiminen FME:n, DuckDB:n ja Ollaman kanssa
RAG eli Retrieval-Augmented Generation kattaa AI-mallien ja ainutlaatuisten tietojesi välisen kuilun. Haemalla asiaankuuluvat tiedot asiakirjoistasi ja syöttämällä ne tekoälymalliin, voit luoda tarkempia, kontekstikohtaisia vastauksia. Tämä opetusohjelma osoittaa, kuinka FME:n avulla luodaan matalakoodin RAG-työnkulku, jonka avulla voit kysyä paikalliselta LLM:ltä (kuten Ollamalta) kysymyksiä käyttämällä asiakirjaasi kontekstina.
Ohjaamme sinut näiden vaiheiden läpi:
- Tekstin poimiminen asiakirjasta.
- Tekstin valmistelu.
- Tekstin esittäminen vektoriavaruudessa.
- Sen tallentaminen ja analysointi tietokantaan.
- Haetaan osuvaa sisältöä.
- Sisällön käyttäminen AI-mallin kyselyyn.
Esimerkkimme: Kysyminen ALADIN-mallista
Kuvittele, että analysoit tieteellistä artikkelia kaupunkien lämpösaarista. Päivän kysymys on: “Mikä on ALADIN-malli?” 🐫☀️
Käytämme FME:n tuottamaa työnkulkua paperin asiaankuuluvien osien hakemiseen ja kontekstitietoisen vastauksen antamiseen paikallisesta tekoälymallista.
Vaihe 1: Tekstin purkaminen asiakirjasta
Käyttötapaus : Aloita PDF-tiedostosta tai vastaavasta asiakirjasta ja muunna se luettavaksi tekstiksi käsittelyä varten.
Esimerkkidokumenttimme:
- Otsikko : Arvio kaupunkien vaikutuksista pintaan ja näytön tason lämpötilaan ALADIN-ilmastopohjaisessa SURFEX-maapintamallissa Budapestille
- Tekijät : Zsebeházi & Mahó
- Julkaistu : Atmosphere , voi. 12, ei. 6, 709
Käytetty lukija: PDF
Tämä ominaisuustyyppi edustaa PDF-tiedostoista purettua tekstisisältöä.
FME:n kooditon muotoilu tekee yhteyden muodostamisesta PDF-tiedostoon yksinkertaista. Vedä ja pudota tiedosto, määritä asetukset ja olet valmis käsittelemään tekstiä. Voit myös poimia kuvia, tekstin sijaintia jne. Kaikki nämä voivat syöttää sisäisen tietokantaasi.

Vaihe 2: Tekstin valmistelu upottamista varten (tietokannan objektit)
Jaa suuri teksti pienemmiksi, merkityksellisiksi paloiksi, jotta se voidaan tallentaa saadaksesi tarvittavat tiedot tietokantaan. Jokaisella palalla on myöhemmin sen koordinaatit vektoriavaruudessa.
Käytetyt muuntajat :
- StringReplacer : Puhdistaa ja normalisoi tekstin.
- SubstringExtractor : Jakaa tekstin hallittavissa oleviin osiin (esim. 1 000 merkkiä), joissa on päällekkäisiä segmenttejä kontekstin säilyttämiseksi paremmin. Käytimme FME:tä saadaksemme säännöllisen lauseen oikein.
On tärkeää tasapainottaa kappaleen koko ja sisältö. Tekoälyn on helpompi käsitellä pienempiä paloja, mutta niiden on silti sisällettävä tarpeeksi merkityksellistä tietoa, jotta kysymykseesi voidaan vastata tehokkaasti.
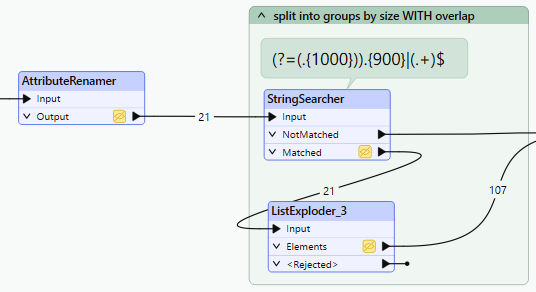

Vaihe 3: Tekstin esittäminen vektoriavaruudessa
Muunna tekstipalojen merkitys numeerisiksi esityksiksi (vektoreiksi) vertailua ja hakua varten.
Käytetyt muuntajat :
- HTTPCaller : muodostaa yhteyden Ollaman API:hen vektoriesitysten luomiseksi.
Tässä vaiheessa jokainen tekstipala muunnetaan vektoriesitykseen , joka vangitsee sen semanttisen merkityksen. Näiden vektorien avulla järjestelmä voi verrata tekstikappaleita niiden sisällön perusteella, mikä mahdollistaa samankaltaisuuteen perustuvat haut myöhemmin.
Miksi käyttää Ollamaa?
- Paikalliset tekoälymallit varmistavat tietojen yksityisyyden (tässä nomic-embed-text).
- REST API tekee integroinnista yksinkertaista ja joustavaa, koska upottamista varten on oma päätepiste.
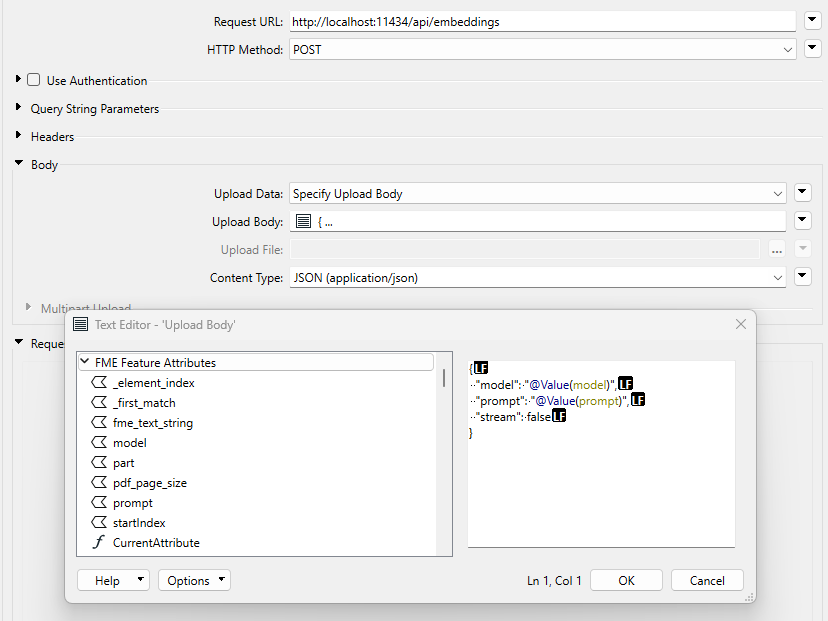
HttpCaller-parametrit
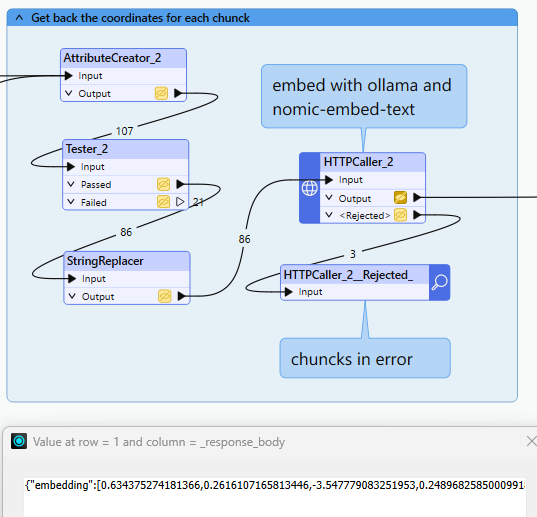
Kyselyn Json-tuloste, yli 700 ulottuvuuden vektori, joka edustaa tiedon sijaintia
Vaihe 4: Tallenna ja etsi relevanttia tekstiä
Tallenna vektoriesitykset ja löydä nopeasti kysymyksellesi osuvin teksti.
- FeatureWriter : Tallentaa vektoritiedot Parquet-tiedostoon tehokkuuden parantamiseksi.
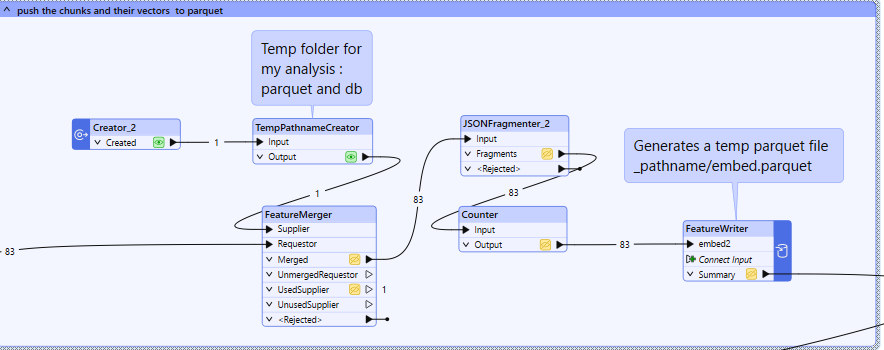
Tallentaa tekstiä ja vektoreita väliaikaiseen parkettitiedostoon
Upota kysymyksesi toiseen haaraan. Kysyäksesi lähimmät vektorit tarvitset kysymyksesi sijainnin.
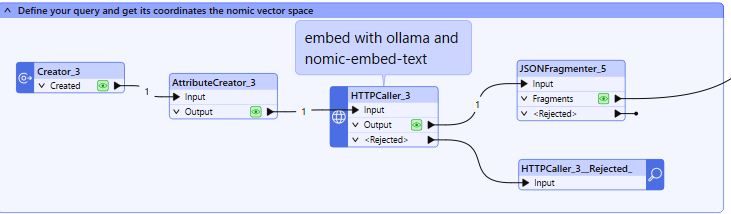
Kysymysten luominen ja kutsu upottamiseen päätepisteeseen
Lataa tietokantaan ja tee kysely SQLExecutorin kautta.

#Delimiter to send the requests to in memory duckdb in sequence
FME_SQL_DELIMITER ;
#Install Vector Similarity Search Extension to be able to create an index and speed up search
INSTALL vss;
LOAD vss;
#Create temp table from parquet. FLOAT[768] is an array of 768 dims (same as embedding from nomic)
CREATE TABLE embeddings AS SELECT id, text, json_extract(content, '$')::FLOAT[768] AS embedding FROM read_parquet('embed.parquet');
#Index creation, metric is specified to cosine but this is the default one)
CREATE INDEX idx_embeddings_vss ON embeddings USING HNSW(embedding) WITH (metric = 'cosine');
#Select the text from the 5 top answers (meaning closest in vector space)
SELECT text FROM embeddings ORDER BY array_distance(embedding,@Value(_response_body)::FLOAT[768]) LIMIT 5;
DuckDB antaa sinun tehdä kyselyitä näistä vektoreista löytääksesi kysymyksesi kannalta oleellisimmat. Jos haluat käyttää toista tietokantaa, FME tekee vaihtamisesta saumatonta.
Miksi käyttää FME:tä? : FME:n koodittomien tietokantaliittimien avulla voit mukauttaa työnkulkua mihin tahansa tietokantaan ilman teknisiä esteitä.
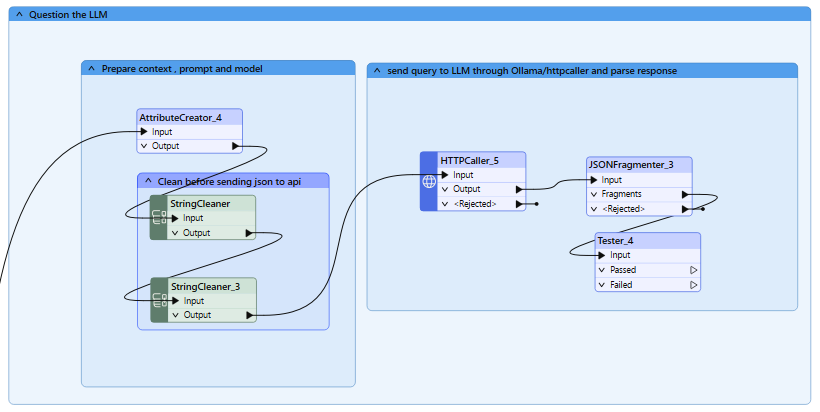
Vaihe 5: Kysy AI-mallilta kysymyksesi
Käyttötapaus : Yhdistä haettu teksti kysymykseesi ja lähetä se tekoälymalliin vastausta varten.
Käytetyt muuntajat :
- AttributeCreator : Yhdistää kysymyksen ja haetun tekstin. Valmistelee POST-pyyntösi JSON-rungon.
- StringCleaner : Auttaa poistamaan kielletyt merkit JSON-muodossa lähetettävästä tekstistä.
- HTTPCaller : Lähettää yhdistetyt tiedot Ollamaan vastausten luomista varten. Varo kontekstin kokoa ja aikakatkaisua.
Tekoälymalli käyttää haettuja tekstikappaleita kontekstina luodakseen tietoisen ja asiaankuuluvan vastauksen kysymykseesi.
{
"model": "@Value(model)",
"prompt": " Please use the following article context : @Value(text). Then, based on it and your knowledge, answer : @Value(prompt)",
"stream": false,
"options": {
"num_ctx": 4000
}
}
Vaihe 6: Tulosten esittäminen
Muotoile ja toimita tekoälyn vastaus haluamassasi muodossa.
Käytetyt muuntajat :
- JsonFragmenter : Purkaa vastauskentän tekoälyn JSON-lähdöstä.
- FeatureWriter : Tulostaa tulokset tiedostoon tai tietokantaan.
FME:n avulla voit tulostaa tulokset JSON- tai CSV-muodossa tai jopa työntää ne suoraan kojelaudoihin tai muihin alavirran järjestelmiin.
Miksi käyttää tätä työnkulkua?
FME:n vahvuudet :
- Yhdistä ilman koodia : Työskentele helposti PDF-tiedostojen, tietokantojen tai sovellusliittymien kanssa ilman koodia.
- Joustavat tietokantavaihtoehdot : Vaihda tietokantoja (esim. DuckDB PostgreSQL:ään) vähällä vaivalla.
- Saumaton API-integraatio : Yhdistä vaivattomasti sovellusliittymiin, kuten Ollaman REST-sovellusliittymään tekoälypohjaista käsittelyä varten.
Ollaman edut :
- Paikalliset tekoälymallit : Varmistaa tietojen yksityisyyden ja hallinnan.
- REST API : Yksinkertaistaa vektorien luomista ja kyselyitä.
DuckDB edut :
- Muistissa oleva suorituskyky : Nopea käsittely ja kyselyn suoritus.
- SQL-yhteensopivuus : Tuttu syntaksi helpottaa integrointia.
- Asennusta ei tarvita : Koska aiomme julkaista tämän FMEHubissa, tämä on kevyempää kuin esimerkiksi Postgresin asentaminen.
Seuraavat vaiheet: Työnkulun parantaminen
Tässä on muutamia tapoja rakentaa tälle perustalle:
- Laajenna tietolähteitä : Integroi reaaliaikaiset sovellusliittymät, pilvitallennus, rasteridata tai verkkokaappaus. FME:llä kaikki tiedot ovat tavoitettavissa.
- Paranna automaatiota : Ota työnkulku käyttöön FME-palvelimella aikataulutusta ja skaalautuvuutta varten.
- Kokeile lisäasetuksia : Käytä tarkempia malleja tai parametreja, kuten lämpötilaa, nähdäksesi, kuinka se vaikuttaa vastaukseen.
- Vuorovaikutteiset tulokset : Työnnä tulokset kojelaudoille tai ilmoituksiin saadaksesi hyödyllisiä oivalluksia.
Tämä työnkulku näyttää, kuinka FME voi yksinkertaistaa RAG-työnkulkuja yhdistämällä asiakirjasi paikallisiin tekoälymalleihin, kuten Ollama. Pienellä vaivalla voit rakentaa joustavia ja tehokkaita ratkaisuja, jotka on räätälöity tarpeisiisi. Jos olet kiinnostunut jatkamaan tätä lähestymistapaa, ota rohkeasti yhteyttä saadaksesi lisätietoja!

 Svenska
Svenska English
English
