
Konteksti
Pitkän ajan koulutusmateriaalimme ovat olleet pääasiassa englanninkielisiä. Ottaen huomioon Suomen datalähtöisen työvoiman vahvan kielitaidon, tämä ei ole aiheuttanut merkittäviä ongelmia. On syytä huomata, että Suomessa on kaksi virallista kieltä, ruotsi ja suomi, sekä ainakin kaksi muuta saamen kieltä, joita Euroopan pohjoisimpien alueiden alkuperäisyhteisöt puhuvat.
Tänä vuonna teimme kuitenkin strategisen päätöksen kohdentaa resursseja yleisten koulutusmateriaaliemme suomenkielisten versioiden tekemiseen. Aluksi suoraviivaiselta tuntunut prosessi, joka sisälsi kaksi vaihetta: “Käännä Wordiin” ja “Petri, voisitko tarkistaa?”, kehittyi monimutkaisemmiksi ja odottamattoman nautinnollisemmiksi, osittain Wordin kohtaamien rajoitusten vuoksi.
Tämä toteutus toimii katalysaattorina tulevalle opetusohjelmalle, jossa perehdymme prosessiin, jolla rakennetaan prosessi Word-asiakirjan dynaamiseksi päivittämiseksi hyödyntämällä avoimen lähdekoodin koneoppimistyökaluja.
Lähestyä
Kun perinteiset menetelmät epäonnistuivat, etsimme ratkaisua FME:n ja avoimen lähdekoodin käännösmalleista.
Jotta asiat olisivat mielenkiintoisia, pyrimme säilyttämään asiakirjan asettelun samalla kun korvaamme sen tekstin.
Tässä ovat tärkeimmät vaiheet:
- Pura tekstielementit ja niiden sijainnit Word-asiakirjan XML-puusta (KYLLÄ Word docx on xml ja me kaikki rakastamme XML:ää, eikö niin?).
- Vie teksti CSV-muotoon käännettäväksi.
- Käännä tekstiä tekoälyllä.
- Päivitä alkuperäinen DOCX-tiedosto käännetyllä sisällöllä.
Docx on XML ja FME rakastaa XML:n tekstin purkamista
Pura DOCX-tiedosto ja pura “t”-elementit XML-puusta. Tämä vaati vain muutaman muuntajan.

- TempPathnameCreator : Luo väliaikainen kansio.
- ZipExtractorAnyExtension : Pura sisältö tällä muuntajalla, jonka on kehittänyt Takashi Iijima, FME-yhteisön keskeinen hahmo ja joka tunnetaan oivaltavasta FME- ja Python-integraatiota käsittelevästä blogistaan. (Erityinen maininta myös Don Murraylle hänen panoksestaan.)
- Tester: Tunnista ja valitse “document.xml”-tiedosto lukuisten purettujen tiedostojen joukosta.
- FeatureReader: Pura teksti “t”-elementti sen merkittävän puunhakutyökalun ansiosta ja saat niiden sijainnit puussa.

- VariableSetter : Tallenna väliaikaisen kansion polku tulevia päivityksiä varten.
Käännös: Olennainen mutta työläs tietojen valmistelu
Nyt kun olemme saaneet tekstielementit käännettäväksi, virtaviivaistamme prosessia viemällä ne väliaikaiseen CSV-tiedostoon. Tämä parantaa työnkulkumme kestävyyttä ja modulaarisuutta, mikä helpottaa vuorovaikutusta ulkoisten testaus- ja eräkäsittelytyökalujen kanssa.

- Luomme erillisen väliaikaisen kansion sekaannusten välttämiseksi.
- Asettaaksemme FeatureWriterin sijainnin, käytämme FME-temppua: FeatureMerger 1:1-parametrilla.

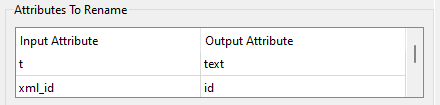
- AttributeRenamer avulla voimme mukauttaa määritteiden nimiä.
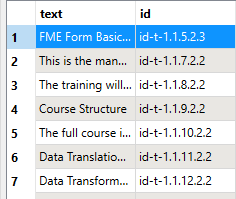
- Lopuksi kirjoitamme CSV-tiedoston FeatureWriterillä ja varmistamme, että tavujärjestysmerkki (BOM) poistetaan oikeaa muotoilua varten.

Trendikäs/kuplaosa: AI-käännös käyttämällä paikallista ML-mallia
Vaikka tekstielementtien kääntämiseen on tässä vaiheessa saatavilla useita sovellusliittymiä, päätimme sukeltaa syvemmälle uusimpiin ML-malleihin ja työkalusarjoihin. Tätä tarkoitusta varten päätimme asentaa Helsingin yliopiston kehittämän mallin, johon pääsee Hugging Face -portaalin kautta: https://huggingface.co/Helsinki-NLP/opus-mt-en-fi.
Alkuvaikutelmat
Koneoppimisen maisema on kehittynyt merkittävästi saavutettavuuden suhteen. Hugging Facen kaltaiset alustat eivät ainoastaan tarjoa dokumentaatiota, vaan tarjoavat myös mahdollisuuksia testata malleja, ladata tietojoukkoja ja käyttää testiesiintymiä, mikä merkitsee huomattavaa edistystä muutaman vuoden takaisesta työkaluista, kuten OpenCV tai TensorFlow.
Toteutus
Asennus
Hugging Facen antamien ohjeiden mukaisesti alkuperäisen käsikirjoituksen määrittäminen on erittäin yksinkertaista.
- Luo ensin oma virtuaaliympäristö Pythonin sisäänrakennetulla venv-moduulilla:
python -m venv /pathtoenvironment
- Katso heidän dokumentaatiostaan saadaksesi testiskripti ja tutustu työkalun toimintoihin.
Huomautus: Muista riippuvuuksien vaatima Python-versio. Lisäksi, jos aiot käyttää GPU-kiihdytystä, varmista yhteensopivuus Python-versiosi ja CUDA-ajureiden kanssa. Tällaiset yhteensopivuusongelmat ovat kuitenkin paljon harvinaisempia kuin muutama vuosi sitten. Käytimme asennuksessa Python 3.11.8.
Sopeutuminen
Muokkaa Python-testikoodia niin, että se lukee tekstielementtejä sisältävän CSV-tiedoston, käännä ne ja luo uusi CSV-tiedosto, joka sisältää käännetyt elementit ja niitä vastaavat tunnukset. Tämä varmistaa, että voit helposti päivittää alkuperäisen sisällön myöhemmin.
Ota yhteyttä, jos haluat täydellisen toimivan esimerkkikoodin.
Tämän prosessin virtaviivaistaminen yksinkertaistaa merkittävästi käännöksen itsenäistä testausta. Voimme nyt integroida sen saumattomasti FME:n kanssa.
FME soittaa tekoälytyökalulle: Tehokas SystemCaller
FME, joka tunnetaan Sveitsin armeijan veistä muistuttavasta monipuolisuudestaan, loistaa erityisesti kyvyssään käyttää ulkopuolisia työkaluja vaivattomasti. Skenaariossamme hyödynsimme SystemCalleria Python-työkalumme suorittamiseen virtuaaliympäristössä. Jos jollain on näkemyksiä tämän suorittamisesta suoraan PythonCallerin kautta, otamme mielellämme vastaan heidän panoksensa.
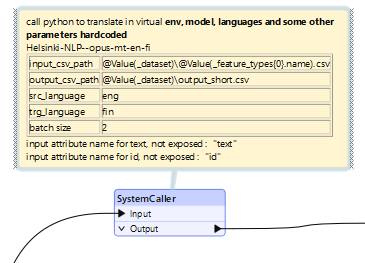
- Valmistele erätiedosto, joka sisältää työkalun suorittamiseen tarvittavat vaiheet. Jälleen kerran Chat-GPT:n kaltaiset työkalut voivat nopeuttaa tätä prosessia. Alla on lyhennetty esimerkki luomastamme translate.bat-tiedostosta:
rem Activate the virtual environment cd /d D:\ cd ai2 call mynewenv\Scripts\activate.bat echo Virtual environment activated. rem Call the Python script with parameters python test03042024.py %1 %2 %3 %4 %5 rem Deactivate virtual environment deactivate
- Kutsu komentotiedosto tai PowerShell-komentosarja SystemCallerin kautta hyödyntäen FME:n muuttujia parantaaksesi joustavuutta.
Word-asiakirjan päivittäminen
Kun käännetyt tekstielementit on nyt tallennettu CSV-tiedostoon, seuraava vaihe on XML-tiedoston päivittäminen ja tuloksen pakkaaminen.
Päivitetään XML
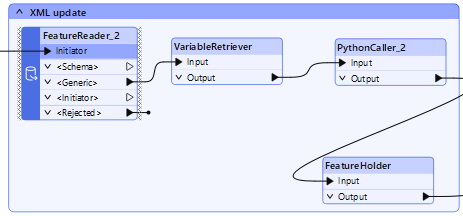
Jatketaan document.xml-tiedoston päivittämistä:
- Lue käännetyt elementit sisältävä CSV. FME:n käyttäminen tässä vaiheessa tehostaa testausta, tietojen laaduntarkastuksia ja mukautuu erityisiin käyttötapauksiin.
- Nouda document.xml-tiedoston polku VariableRetrieverillä.
- Käytä PythonCalleria kartoittamaan XML-puuelementit ja suorittamaan päivityksen. Alla on koodinpätkä tämän tehtävän helpottamiseksi. Nämä kirjastot on jo asennettu FME Python -kansioon. Päätoimintojen alle integroimme ne FME-objekteihin.
def update_xml_with_translations(xml_path,translation_mappings):
parser = etree.XMLParser(remove_blank_text=True)
tree = etree.parse(xml_path, parser)
root = tree.getroot()
for xml_id, translated_text in translation_mappings.items():
# Find the element by its XML ID
print(xml_id)
elem = find_element_by_id(root, xml_id)
if elem is not None:
elem.text = translated_text # Update the text content
print(elem.text)
tree.write(xml_path, pretty_print=True, encoding='utf-8', xml_declaration=True)
def find_element_by_id(root, xml_id):
# Split the xml_id into indices
indices = xml_id.split('.')[2:]
# Traverse the XML tree to find the element
elem = root.find('.//w:body', namespaces=root.nsmap)
for index in indices:
print(elem)
index = int(index) - 1
try:
elem = elem[index]
except (IndexError, TypeError):
print("error")
return None # Element not found
return elem
DOCX:n vetoketju
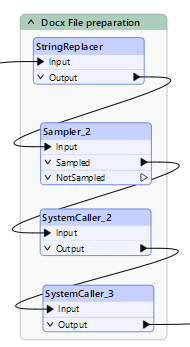
Olemme lähestymässä viimeistä vaihetta! Kansion pakkaamiseksi käytämme DOS-peruskomentoja SystemCallerin kautta, ja FME auttaa nimeämisessä ja parametroinnissa.
Ensisijaiset komennot, joissa “&&” mahdollistavat vaiheiden yhdistämisen, ovat seuraavat:
- xcopy: Tämä kopioi väliaikaiset tietosi haluamaasi kansioon.
- powershell Compress-Archive: Tämä pakkaa kansiosi. Muista “*” estääksesi alikansion luomisen, mikä saattaa häiritä DOCX:ää.
- rename: Tämä nimeää ZIP-tiedostosi uudelleen tunnisteella “.docx”.
Tarkista tulos!!
Onnittelut! Kun pakkaaminen on valmis, voit nyt avata Word-tiedostosi ja ihmetellä (ja/tai nauraa) käännettyä sisältöä.

Tärkeimmät kohdat tulosteen laadusta:
- Tyylin ja asettelun eheys: Säilytämme alkuperäisen asiakirjan tyylin ja asettelun varmistaaksemme ulkoasun yhtenäisyyden.
- Kääntämättömät otsikot ja taulukot: Otsikot ja taulukon sisältö jää kääntämättä, koska niitä ei tallenneta “t”-elementteihin, mikä vaatii lisäoptimointia.
- Käännösten omituisuudet: Jotkut käännökset saattavat vaikuttaa lapsellisilta ja muistuttavat nuorten suomenkielisten kielitaitoa. Tämä johtuu kappaleiden segmentoinnista lyhyiksi “ajoiksi”, joita FME voi auttaa ratkaisemaan.
- Suorituskykyongelmat: Päättelyvaihe, joka on erityisen havaittavissa ilman korkean suorituskyvyn GPU:ta, voi olla hidas tässä mallissa.

Johtopäätös
Tässä opetusohjelmassa ja kokemuksemme pohdinnassa olet nähnyt avoimen lähdekoodin koneoppimisen ja FME:n fuusioitumisen nykyaikaisiin käännöstehtäviin. Laajemmin se tarjoaa oivalluksia tietojen muunnosputkien luomiseen, jotka integroivat FME:n huippuluokan työkaluihin paikallisesti, mikä eliminoi riippuvuuden API-liittymistä.
Tekoälyprojektien jakamisalustojen, kuten Hugging Facen, ilmaantuminen yhdistettynä avoimien mallien saatavuuteen arvostetuilta tutkimuslaitoksilta, kuten Helsingin yliopistolta, on demokratisoinut kokeiluja moderneilla työkaluilla. Innovaatiosilmukka ei ole koskaan ollut lyhyempi. Näiden edistysten integrointi prosesseihisi ja tuotteisiisi on virtaviivaistettu FME:llä, joka on merkittävä työkalu, joka helpottaa vankkojen konseptien nopeaa rakentamista. Nämä ovat muiden kuin koodaajien ymmärrettäviä selkeiden, uudelleenkäytettävien työlohkojen ansiosta, jotka voidaan laajentaa yleisempiin käyttötapauksiin.

 Svenska
Svenska English
English
